
La communauté des essais de véhicules électriques doit faire face à des produits de plus en plus complexes et à des cycles de développement de plus en plus rapides, ce qui signifie que les laboratoires d’essais sont soumis à une pression constante. La capacité à analyser efficacement les données de test n’a donc jamais été aussi cruciale. Les coûts doivent être maintenus à un niveau aussi bas que possible, alors que des quantités croissantes de données provenant de capteurs sont traitées. Les ingénieurs doivent contrôler et analyser les données d’essai en temps réel, quelle que soit la quantité de données à examiner. Il n’est donc pas étonnant qu’ils recherchent de nouveaux moyens d’améliorer l’efficacité des tests et de réduire le risque de données de mauvaise qualité.
Lors de l’acquisition, les signaux électriques et mécaniques sont mesurés à des taux d’échantillonnage de l’ordre du kilohertz et doivent être hautement synchronisés. Ces tests, en particulier, génèrent une quantité impressionnante de données. Le véritable défi consiste à stocker et à conserver ces données. Le traitement de volumes aussi importants de données structurées et non structurées nécessite un back-end adaptable et évolutif. Pour faire face à l’évolution constante des exigences, des configurations, des extensions de paramètres et des taux d’échantillonnage, il est utile de séparer les données chaudes des données froides.
Les “données froides”, auxquelles on accède moins souvent et qui ne sont nécessaires qu’à des fins d’audit ou de post-traitement, sont stockées dans une plateforme de diffusion en continu distribuée qui évolue en fonction des besoins. Les “données chaudes”, auxquelles on accède en temps réel pour l’analyse, sont fournies dans une base de données chronologiques NoSQL. Cette base de données stocke les relevés en toute sécurité dans des grappes redondantes et tolérantes aux pannes. L’agrégation flexible des données garantit que la bonne granularité est disponible à tout moment. Les données peuvent ensuite être rejouées et agrégées de différentes manières pour une analyse détaillée des événements de l’essai. Cette approche permet de minimiser les coûts opérationnels informatiques et l’infrastructure de stockage au sein du laboratoire de test.
L’essai du groupe motopropulseur des véhicules électriques est un cas d’utilisation typique où un back-end de données évolutif offre des avantages significatifs. Une énorme quantité de données est générée, en particulier lors de l’évaluation en temps réel de la puissance et des performances des moteurs électriques. Les débits de données peuvent varier de 10 échantillons/seconde à 4 000 000 échantillons/seconde. Le défi consiste à stocker toutes ces données, tout en les gardant disponibles 24 heures sur 24 et 7 jours sur 7 pour une analyse rapide des flux de données continus et déclenchés.
Pour capturer, analyser et stocker les données, et garantir leur disponibilité pour les applications, Gantner a choisi Apache Kafka, une plateforme de flux de données, pour gérer les données froides, et la base de données distribuée CrateDB pour gérer les données chaudes. Travailler avec ce concept de back-end de données évolutif démontre la puissance de la combinaison de l’edge computing, du traitement des big data et de l’apprentissage automatique.
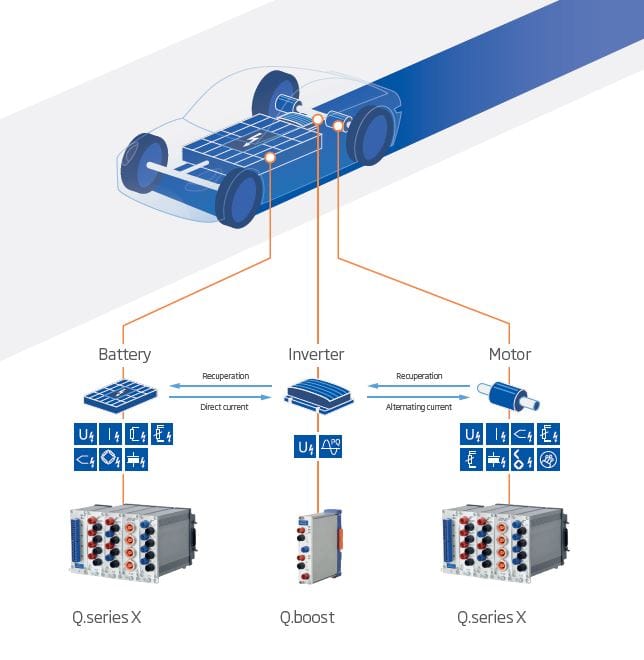
Les laboratoires d’essai utilisent des systèmes spécialisés de contrôle, de surveillance et d’acquisition de données, mais l’intégration nécessaire entre ces systèmes fait souvent défaut, ce qui peut entraîner une détection tardive des défauts dans les systèmes testés. La philosophie de Gantner est de fournir aux clients des interfaces ouvertes pour stocker les données et les envoyer là où ils en ont besoin – ce qui permet une intégration transparente avec n’importe quel outil de surveillance, d’analyse et de création de rapports.
Pour les laboratoires d’essais équipés de systèmes d’essais automatisés, l’interface de programmation d’applications (API) de la société offre un moyen simple d’intégrer la solution dans leurs environnements existants. Les méthodes d’analyse et de détection des défaillances diffèrent selon les applications. Il est donc essentiel de disposer d’interfaces normalisées pour intégrer les architectures, les méthodes de visualisation et les routines de rapport existantes, par exemple pour calculer avec précision le facteur de puissance, la puissance apparente et la puissance réactive à partir de données de mesure brutes.
Grâce à une solution dorsale de données adaptable et évolutive, Gantner Instruments fournit aux laboratoires d’essais la plateforme nécessaire pour saisir, surveiller, analyser et réagir à toute donnée physique en temps réel, quel que soit le volume de données – transformant directement les données en connaissances.
Découvrez la nouvelle plateforme pour des installations de mesure modernes et robustes
La plateforme logicielle GI.bench permet d’accélérer la mise en place des tests, la configuration et la gestion des projets, ainsi que la visualisation des flux de données dans un seul et même poste de travail numérique. Il vous permet de configurer, d’exécuter et d’analyser vos tâches de mesure et de test à la volée. Accédez partout aux données de mesure en direct et aux données historiques.

More articles
Les performances d’EtherCAT combinées à un système d’acquisition de données (DAQ) de pointe : 5 avantages qui vous échappent
Nous avons compilé une liste des 5 avantages les plus significatifs de l'utilisation d'un système d'acquisition de données basé sur EtherCAT. Si vous n'êtes pas encore familiarisé avec EtherCAT, préparez-vous à être éclairé. Si vous faites partie des nombreux ingénieurs qui utilisent EtherCAT dans votre laboratoire d'essais, vous pouvez considérer ceci comme une confirmation de la raison pour laquelle vous faites ce que vous faites - et un excellent moyen de diriger ceux qui pensent encore que l'Ethernet industriel n'est pas adapté aux applications d'essais à haute performance.
Read more...Gantner Instruments Journée technologique 2025
GI Tech Day 2025 - Inscrivez-vous dès maintenant !
Read more...Trois étapes vers l’internet des objets (IdO) ou : D’où proviennent les big data analogiques ?
Le passage à la nouvelle ère de l'internet des objets (IoT), de l'industrie 4.0 ou de l'informatique en nuage se fait à un rythme impressionnant et est également irrésistible dans plusieurs applications industrielles. L'industrie, avec son énorme quantité de machines et de composants de taille, de valeur et de fonction diverses, est confrontée à un grand défi : les données de tous ces actifs doivent être collectées et analysées.
Read more...Systèmes d’acquisition de données portables et mobiles
De nombreuses raisons justifient un système de mesure flexible et robuste qui doit être facile à transporter pour collecter des données de mesure à différents endroits. Il peut s'agir, par exemple, de mesures à court terme sur des machines ou des composants d'usine lors de la mise en service après un entretien, ou de mesures récurrentes sur des ponts ou d'autres ouvrages d'art.
Read more...